前情提要
初探 ElasticSearch Service (以下簡稱 ESS ),
結合 Logstash、Kibana 合稱 ELK,
Elastic Cloud 提供更多的功能雖然蠻多還用不到,但比起自已架設會快相當的多。
因為主系統仍在開發中,只有部份功能上線,所以我選擇 ESS 作為我們的 Log System。
選擇 ESS 的原因如下:
- 快速實現,只需要在 Elastic.io 簡單的操作,便可以有一個功能齊全的服務
- 提供很全面的 Kibana 圖形介面
- 與 .NET 的整合很單純,安裝完 NuGet 套件後,只要設定好 Config 立即可以使用
- 開源且社群活躍,也是目前主流的 Distribution Search Engine
現有配置如下
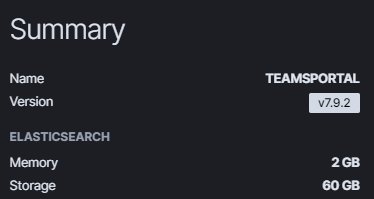
初始的配置更低,是使用最小單位、最少節點的配置。
Memory 只有 1 GB,Storage 有 30 GB。
在初始配置的情況下,JVM memory pressure 常態性達 70% ~ 80%,
這是個異常狀況,在實務上緊急將 Memory Scale Up 到 2 Memory 暫時解除這個問題。
效能問題
追究後面的本質原因的話,是在系統設計上, 每日建立新的 Index,
在官方的 blog 也有提到這樣的實踐方式。
a lot of people use Elasticsearch for logging.
A standard format is to assign a new index for each day.
中略 …
Indices are fairly lightweight data organization mechanisms,
so Elasticsearch will happily let you create hundreds of indices.
但是實務上我產生了太多的 Shards ,這也是初學者常踩的一個雷包,
一不小心就會 Oversharding 可以參考 How to size your shards 進行修正。
這裡我使用了 Reindex 這個 API 來將一些碎小的 Index 作結合(Combine Smaller Indices)。
實作記錄
Reindex 的 SOP
確保 maximum shards 的足夠
ESS 為了避免 Oversharding 導致整個 Cluster 崩潰會有設定一個上限值,
7.x 版本預設為 1000 ,而 Reindex 每一個 Index 都會需要 2 個 Shards (猜測是 SWAP 機制)
以我為例,原本我的 Shards 已達 999 ,當我試著要 Reindex 時會拿到以下會錯誤。this action would add [2] total shards, but this cluster currently has [1000]/[1000] maximum shards open處理的方法也很簡單,只要透過
/_cluster/settings加大cluster.max_shards_per_node即可。1
curl -X PUT localhost:9200/_cluster/settings -H "Content-Type: application/json" -d '{ "persistent": { "cluster.max_shards_per_node": "3000" } }'
實務上我 Reindex 後會刪除碎小的 index,刪除後 Shards 的數量也會下降,
當 Shards 剩餘數量足夠時,我會重設回 1000。執行 reindex ,請確保新舊 index 符合商業邏輯
example:1
2
3
4
5
6
7
8{
"source": {
"index": "staging-aaa-service-2020.06.*"
},
"dest": {
"index": "staging-aaa-service-2020.06"
}
}確保查詢一致
- query 數量為 N
- Reindex
- query 數量為 2N
- delete
- query 數量為 N
執行紀錄
- staging-aaa-system-*
- staging-bbb-server-*
- staging-ccc-service-*
- prod-aaa-system-*
- prod-bbb-server-*
- prod-ccc-service-_ - prod-ccc-service-2020.09-_ 有掉資料(12 萬筆 →9 萬筆)

結果評估
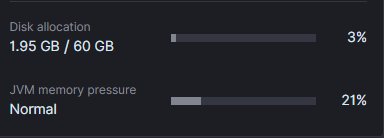
Memory 只有 2 GB,Storage 有 60 GB 時。
ReIndex 並刪除碎小 Indices 前JVM memory pressure常態性達 40%,
執行後,JVM memory pressure約為 20%。
也就是說我可以改用更小(便宜的配置處理目前的資料量)。
改善建議
- 重要敏感的資料,要先備份才能進行 Reindex 的操作
- 下次 reindex 遇到大量資料,要切成更小的單位進行,
比如說每 10 天或每天,減少一次性 reindex 的資料量,
減少失敗與掉資料的可能性發生。 - 需要將系統改用較長的時間周期去建立 Index
- 縮小雲端系統配置。
進階思考
- 如果我想要維持 Daily Indices Created 但是又不想讓 Shard 成長爆量,我應該怎麼作呢 ?
- 或是有什麼機制,可以讓我定期將某些資料 Reindex 嗎 ?
參考
- Shard 的最佳化管理
- What is an Elasticsearch Index?
- [Elasticsearch] 基本概念 & 搜尋入門
- Elasticsearch 7.x node 開放 1000 個 shards 限制
- How many shards should I have in my Elasticsearch cluster?
- 圖解 Elasticsearch 原理
(fin)